缘起
因为需要分析 tfs 提交日志,并按照一定条件(比如,提交信息或者用户名)分类整理,特意写了这个小工具。在使用过程中发现,某些情况下会花费很长时间才能返回处理结果,当时稍稍做了一些优化,已经能满足当时的应用场景了。但是在处理大文件的时候依然会花费很长时间。忍了这么久了,终于有机会做一次效率优化了。
实现逻辑介绍
整体实现逻辑并不复杂,这里稍微作下介绍:
打开需要处理的日志文件(通过 -t 参数传递,如果没指定就默认打开 tfs.txt),然后按行读取,并通过 IsSplitter() 函数判断当前行是否是分割符(由很多 - 组成),如果是就继续读取相关的字段(变更集,用户,日期,注释,项 等),直到遇到下一个分隔符或者文件结尾。找出一条完整的提交记录后,会根据用户指定的过滤条件进行过滤分组,把结果输出到对应的文件中。整个过程完全是在主线程中完成的,没有用到辅助线程。
这里列出两个关键的结构定义:
1 | class ItemInfo |
背景介绍完毕,下面可以进行优化了。
初步观察
启动 ParseTfsLog.exe,然后使用 process explorer 观察运行情况。我录制了一段视频,如下:
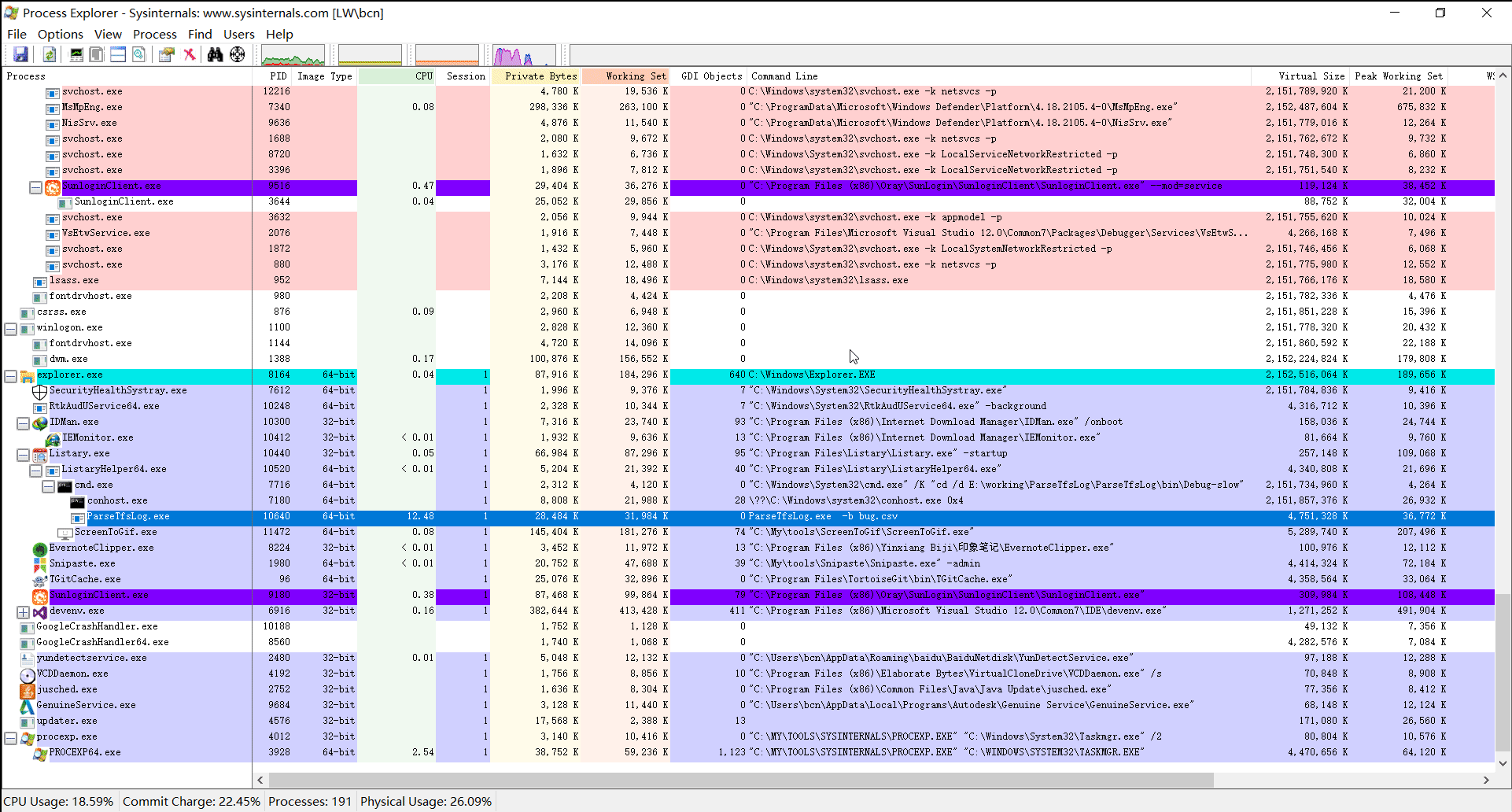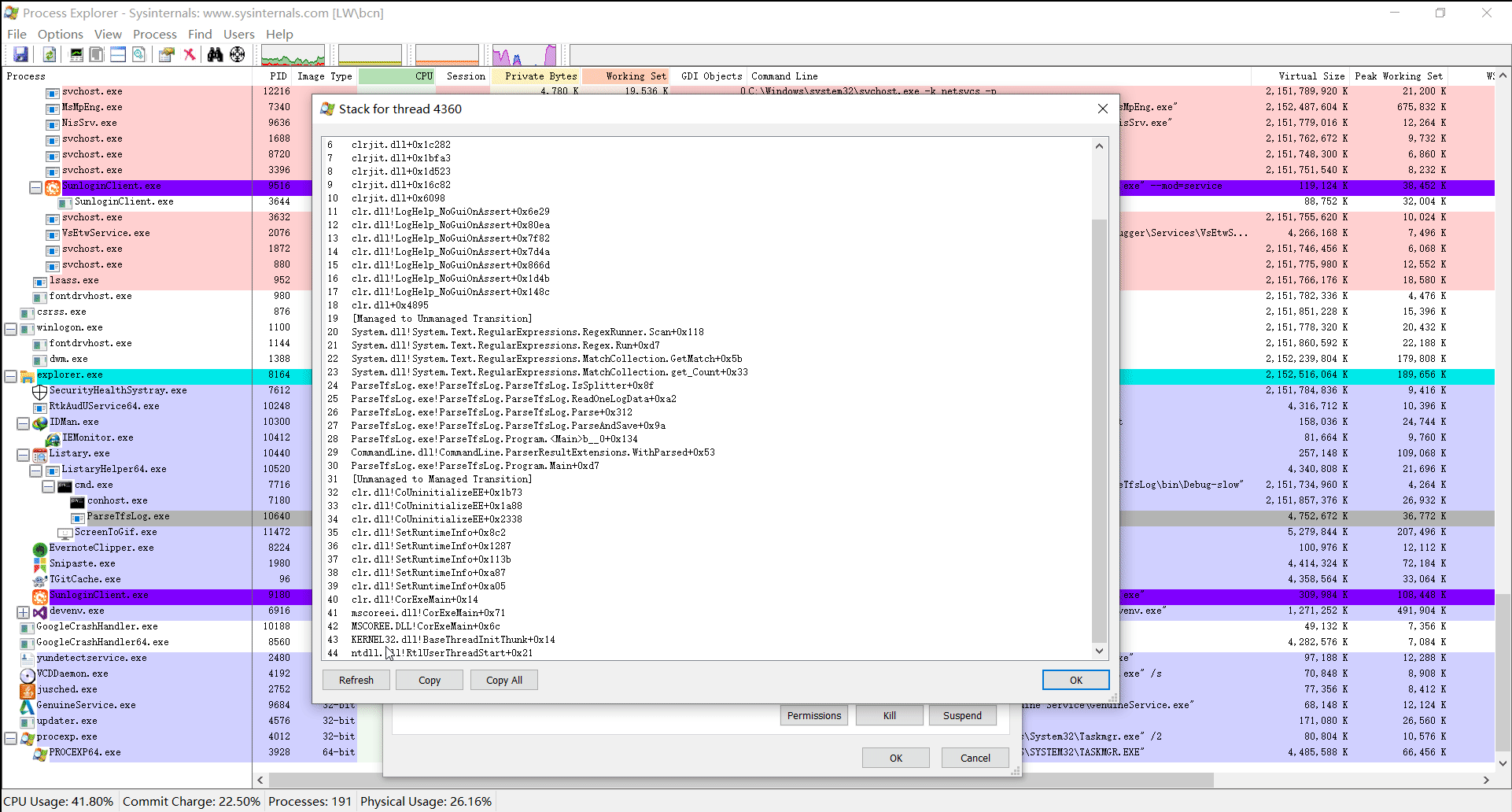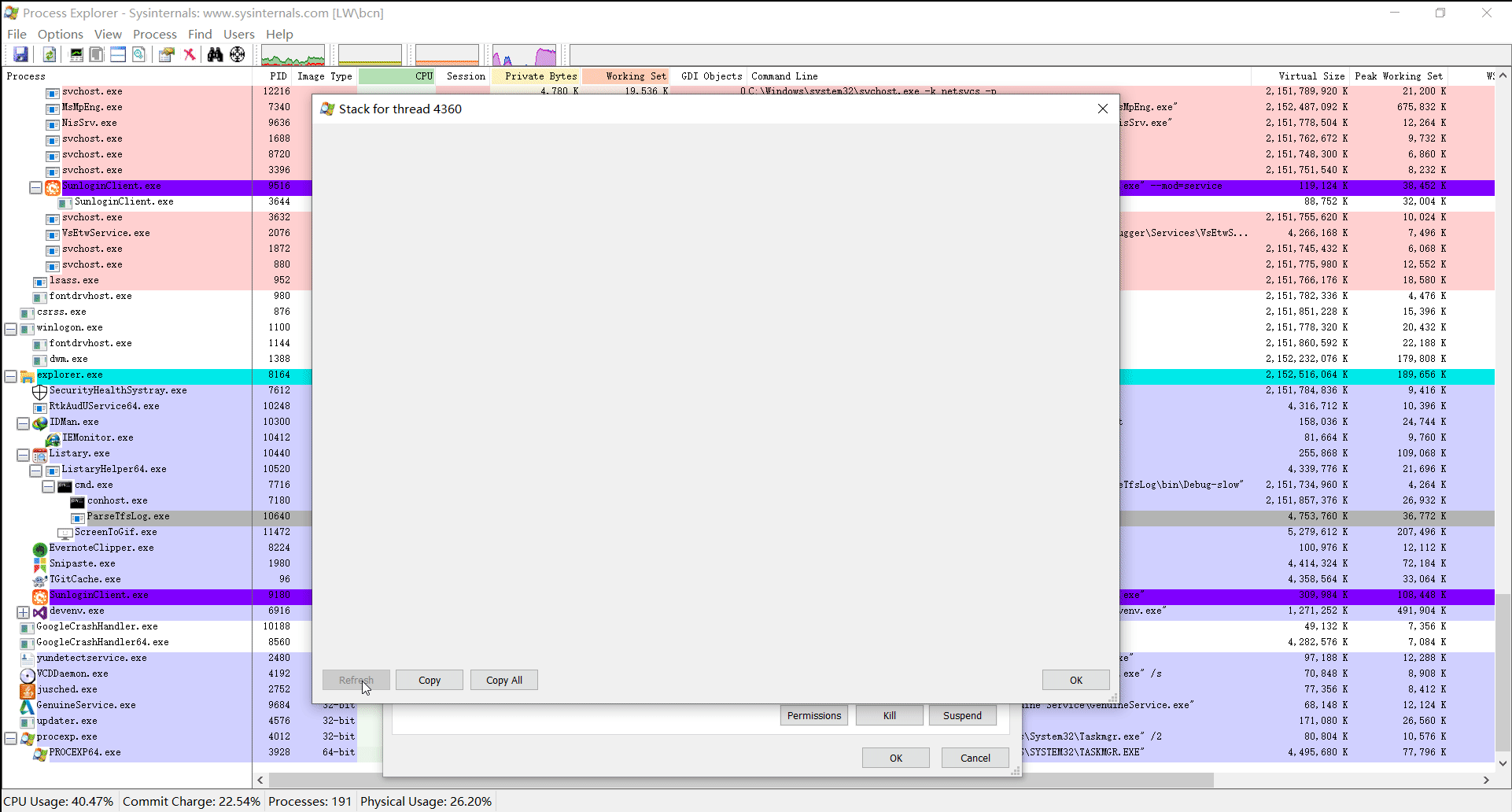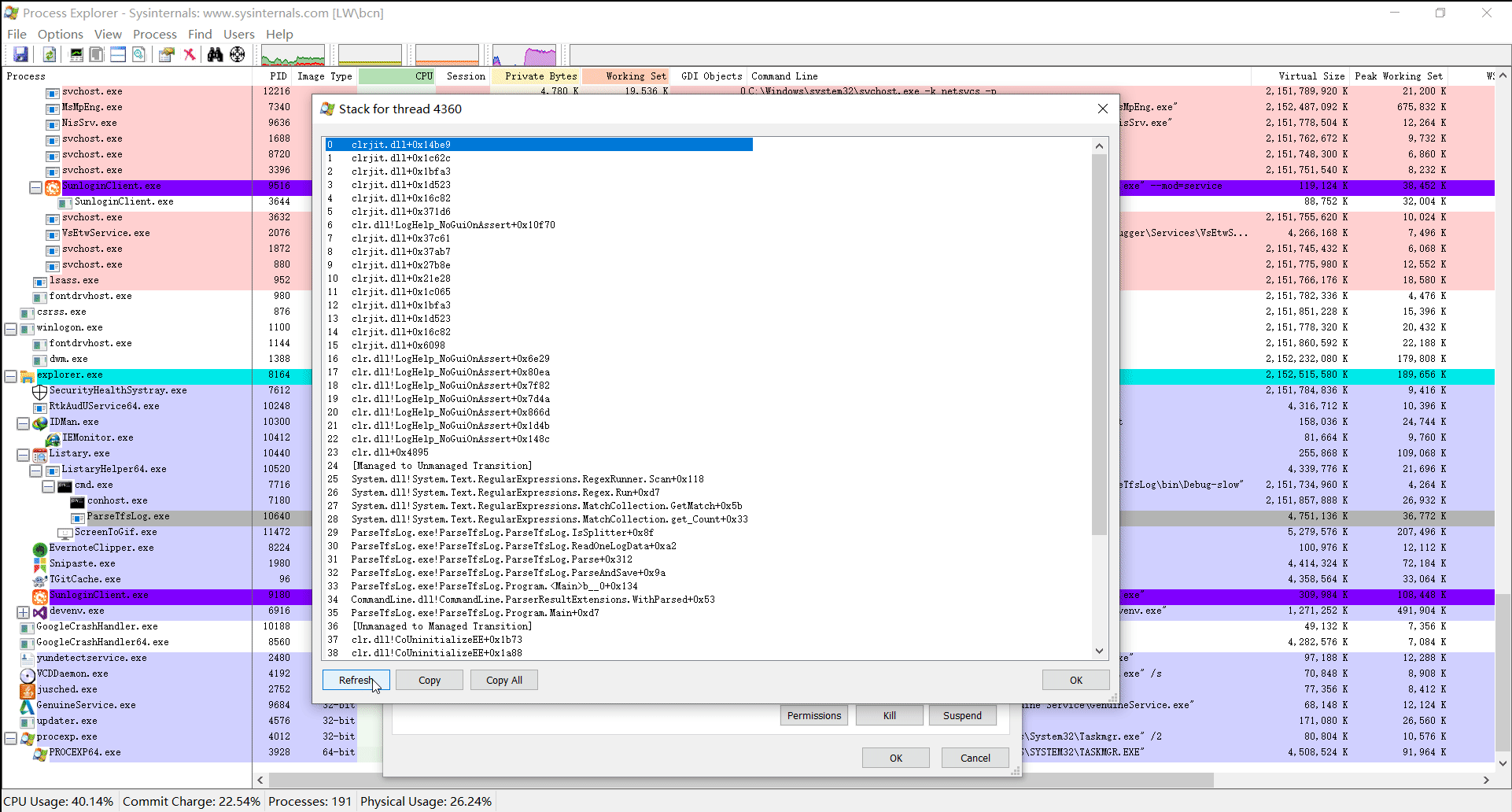
可以看出,ParseTfsLog.exe 在运行过程中占满了一个核心(我的 cpu 是 8 核的,ParseTfsLog.exe 的 cpu 占用率是 12.5 左右)。仔细观察每次刷新时出现在调用栈中的函数名,名为 IsSplitter 的函数基本上每次都会出现。如果每次刷新,同一个函数都出现的话,这个函数就很值得怀疑了。
但是这个函数的实现非常简单,只有三行代码,实现如下:
1 | private static bool IsSplitter(string curLine) |
使用正则表达式判断当前字符串中是否包含 100+ 的 -,如果包含就认为当前行是分隔符。难道正则表达式很慢?不管三七二十一,使用 string.Contains 来替换正则表达式,代码如下:
1 | private static bool IsSplitter(string curLine) |
再次编译运行,一眨眼的功夫结果就出来了。
大文件效率对比
为了更好的感受一下效率的提升,我换了一个更大一些的日志文件来分析,大概有 18.6MB,没优化之前耗时 8676448 毫秒(8676 秒,144 分钟),如下图:
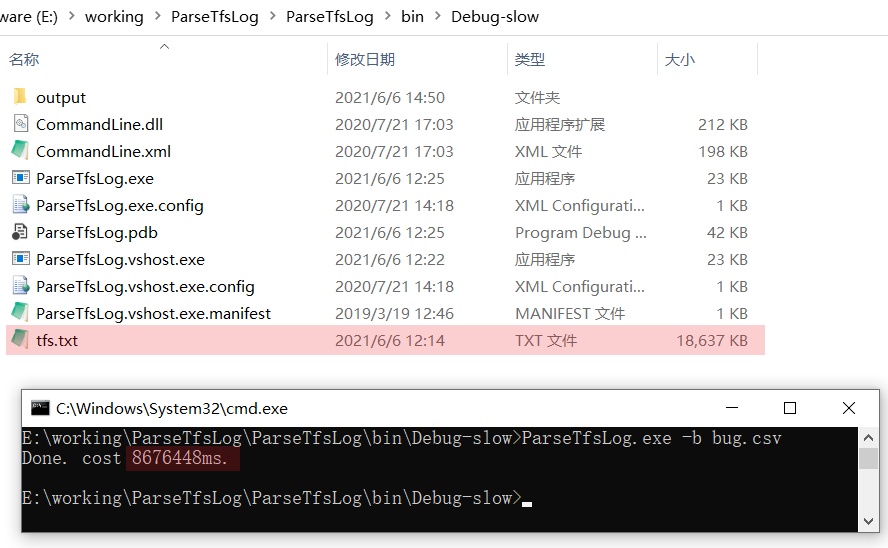
优化后耗时 9428 毫秒,不到 10 秒,如下图:
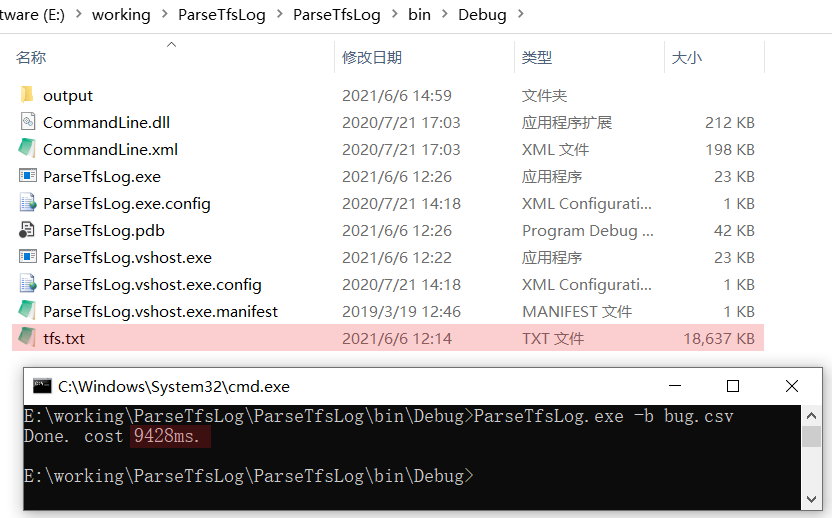
居然提高了 800 多倍!说实话,我真没想到,没优化的时候居然会花那么久才完成。
反思
在开始分析之前,脑子中有各种猜想(有时候想想,自己的脑洞真是够大的):
是不是按行读取文件导致的慢(一般涉及到磁盘,网络的操作都很慢)?
是不是解析的太慢了?
是不是保存结果太慢了?
是不是内存占用太多,
gc太频繁了?…
看来,遇到问题时,可以大胆猜测,但是不能武断,一定要仔细验证。
下载
关于这个小工具的代码经过客户同意后,我已经上传到 github 了,地址为:https://github.com/BianChengNan/ParseTfsLog
欢迎 clone,pr, star。如果觉得 github 慢,也可以到 gitee 下载,地址为:https://gitee.com/bianchengnan/parse-tfs-log
也可以下载压缩包(后续不会更新)
CSDN 下载:https://download.csdn.net/download/xiaoyanilw/20671832
百度云下载:https://pan.baidu.com/s/16lhicg7amBkTua8Iiz2nIQ 提取码: 1sx1
总结
process explorer 真的是观察进程,线程运行情况的神器。很多情况下不用调试器,也不用性能分析工具就能帮我们快速定位问题。
彩蛋
虽然用 process explorer 定位到了问题,也解决了问题,但是多少有些猜的意味。而且正则表达式真这么慢吗?你想知道的尽在续文中。
